TLDR;
Tensors are how AI engines represent everything internally. Computing embeddings is expensive, and there are massive computational speedups to be gained by simply retrieving this data from a cache rather than recalculating it.
Since I want to help our future robotic overlords out (maybe they’ll spare me in the uprising), here is my attempt at solving the AI storage bottleneck: Redstone.
What you’ll learn in this post:
- Why existing caches fall short for ML workloads
- The core design principles behind Redstone
- Detailed architecture (from single-node to distributed)
- Performance trade-offs and failure semantics
- What’s included in the Alpha release
Why Yet Another Cache?
While general-purpose caches like Memcached and Redis are incredible pieces of software, AI workloads possess specific characteristics that demand a tailored approach. Tensors aren’t standard JSON payloads; they are massive, contiguous blocks of memory.
Here is why a specialized ML cache makes sense:
- Read-Heavy Access Patterns: While generic web workloads require balanced read/write profiles, ML inference is overwhelmingly read-heavy. Redstone optimizes heavily for lookup throughput.
- Write-Once, Read-Many (Immutable): Embeddings, once computed, rarely change. This immutability allows us to bypass complex, heavy locking mechanisms that generic caches must maintain to guarantee write consistency.
Redstone is a fully in-memory cache (with tiered memory storage planned for the future) built from the ground up with tensors as first-class citizens. It stores tensors as key-value pairs, allowing inference engines to fetch massive multidimensional arrays over the network with minimal overhead.
Core Design Principles
The architecture of Redstone is driven by five core ideas:
1. “Thick Client, Thin Server” Topology
Redstone intentionally moves cluster intelligence away from the servers. Servers are “dumb” entities; they do not communicate with one another, have no say in cluster management, and are only concerned with storing the data handed to them. The Client holds the brains. It manages the cluster state, routes requests, and monitors node health. This allows for massive, performant scaling by eliminating server-to-server chatter.
2. Zero-Copy Data Movement
Moving megabytes of tensor data over a network is expensive. While Redstone uses gRPC and Protobuf, we minimize data copies as much as possible to save precious CPU cycles. Furthermore, Redstone utilizes Streaming RPCs instead of sending monolithic payloads. This prevents massive tensors from clogging network pipelines.
3. Client-Side L1 Caching
Network hops are the enemy of throughput. Redstone implements a small L1 cache directly on the client side. This allows frequently accessed, smaller tensors to live in the client’s local memory, completely bypassing network overhead and RPC latency.
4. Client Intelligence & Consistent Hashing
Because the client routes all data, it uses a Consistent Hashing ring to map the hash of a key to a specific server. When a node is added or removed, consistent hashing ensures that only a minimal fraction of the data needs to be remapped.
The client actively monitors the cluster via heartbeats. If a server goes silent for an extended period, the client marks it as “dead” and seamlessly updates the routing table.
5. Lock-Free Immutable Writes
As discussed, ML workloads don’t mutate existing embeddings frequently. By treating writes as largely immutable, Redstone avoids the devastating lock contention and cache-line ping-pong that plagues traditional caches under heavy concurrent load.
Architecture & Failure Semantics
Here is a look at the current high-level architecture of Redstone.
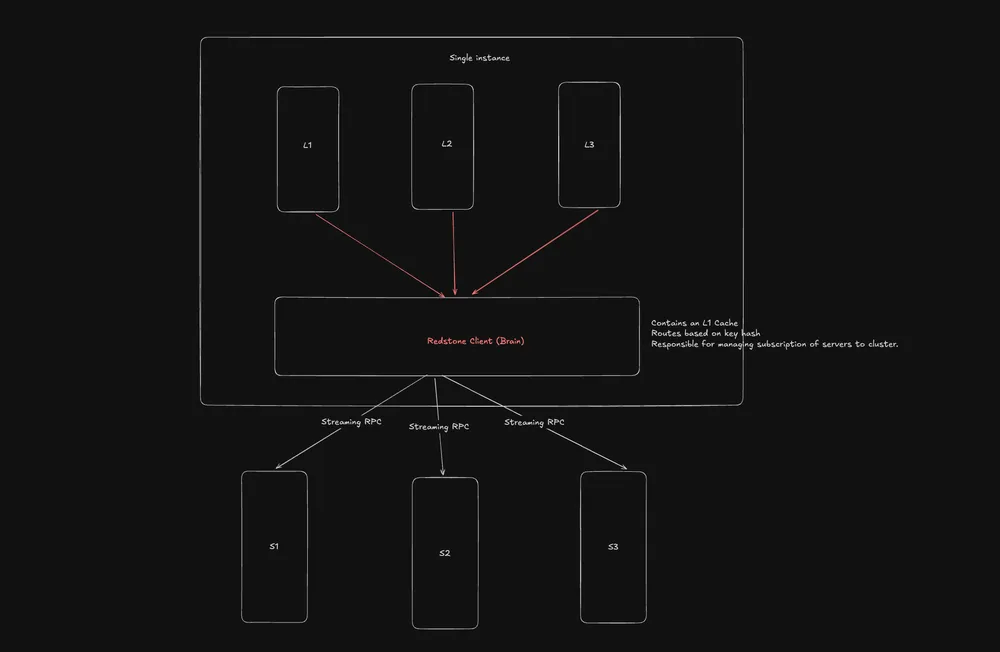
Dealing with Server Death
In distributed systems, failure is a guarantee, not a possibility. When a Redstone server node dies and stops sending heartbeats, the client detects the timeout, purges it from the routing ring, and reroutes subsequent requests.
The Trade-off: Currently, when a server dies, all data on it is lost. Because Redstone is designed strictly as a cache and not a primary source-of-truth database, this is an acceptable failure mode.
Client Responsibilities at a Glance
- Routing: Directing read/write requests to the correct shard.
- Health Monitoring: Evicting dead nodes from the hash ring.
- Lazy Connection Pooling: Dedicated channels to a server are only created exactly when the first request demands it, saving resources.
Alpha Release Features
This is the earliest version of Redstone, focused on proving the core transport and storage mechanics. The Alpha includes:
- Distributed Architecture: Full support for multi-node deployments.
- Tensor-Native Storage: Optimized memory layouts for large payloads.
- Streaming Transport: Chunked gRPC streaming to prevent network bottlenecks.
- L1 Client Caching: Local memory tiers for ultra-fast access.
- LRU Eviction: Standard Least-Recently-Used eviction policies.
- Topology Control: Basic client-side configuration for cluster management.
If you are dealing with ML bottlenecks or just want to take it for a spin, check out the Redstone repository. I would love to hear feedback on the design, or where you’d like to see the project go next.